RNN Encoder-Decoder
序列
在介绍模型之前,先简单地解释一下什么是序列。
序列是一种数据形式,比如一个文本或是一段音频,它的一个很重要的特点就是在其内部有着先后关系
文本的前文和后文之间有着先后关系,音频的前一秒和后一秒有着先后关系,这些关系是不能乱的
如果明白了什么是序列,那么就可以开始接下来的学习了
模型介绍
为了解决如语言翻译这些问题,一种模型于《Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation》被提出
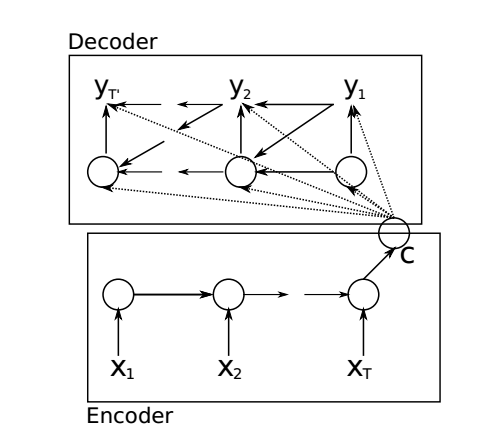
模型主要由两个部分组成
这两个部分通过一个语义向量C连接而成
Encoder
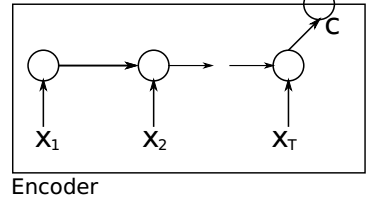
该部分使用RNN将原序列压缩成一个固定长度的语义向量C,每个$X_i$都代表着一个经过embedding(词嵌入)的词语,它们按顺序输入RNN,$X_T$对应的隐状态就是我们需要的语义向量C
Decoder
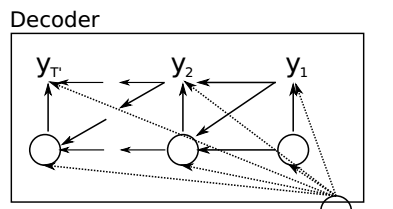
我们知道原本RNN隐状态的计算方式为
在Decoder部分,计算方式为
将语义向量作为影响因素加入了隐藏层的计算
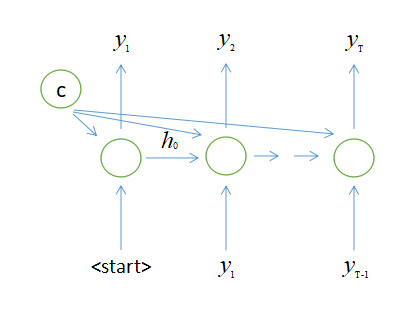
或许这样会更加清楚,其中\是代表序列开始的占位符
值得注意的是,我们在训练阶段,输出的$yi$与生成$y{i+1}$时输入的$yi$并不相同,为了使生成的结果更为精确,输入的$y_i$取自我们想要得到的结果; 而在使用阶段,则将输出的$y_i$作为生成$y{i+1}$时输入的$y_i$
基础的Seq2Seq模型还有很多缺陷,之后会继续介绍有更佳性能的变体
仅供参考的Tensorflow实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| def Encoder(input_data, rnn_size, num_layers):
'''
- input_data: 经过embedding的输入数据
- rnn_size: 每个rnn_cell中units的个数
- num_layers: rnn_cell的个数
'''
def get_lstm_cell(rnn_size):
return tf.nn.rnn_cell.LSTMCell(rnn_size)
stack_lstm = tf.nn.rnn_cell.MultiRNNCell([get_lstm_cell(rnn_size) for _ in range(num_layers)])
encoder_output, encoder_state = tf.nn.dynamic_rnn(stack_lstm, input_data, dtype=tf.float32)
# encoder_state即是我们要的语义向量
return encoder_output, encoder_state
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| def Decoder(target_data, rnn_size, num_layers, c, start_token, end_token, length, decoder_embedding_table):
'''
- target_data: 经过embedding的目标数据
- rnn_size: 每个rnn_cell中units的个数
- num_layers: rnn_cell的个数
- c: 语义向量
- start_token: 开始标志占位符
- end_token: 结束标志占位符
- length: target数据中最大的长度
- decoder_embedding_table: 在Decoder端用来embedding的表
这里的Helper比较难理解
对Tensorflow中seq2seq使用方法的解释,对理解Helper有一定帮助
https://applenob.github.io/tf_dynamic_seq2seq.html
'''
def get_lstm_cell(rnn_size):
return tf.nn.rnn_cell.LSTMCell(rnn_size)
stack_lstm = tf.nn.rnn_cell.MultiRNNCell([get_lstm_cell(rnn_size) for _ in range(num_layers)])
# train_decoder
with tf.variable_scope('decode'):
train_help = tf.contrib.seq2seq.TrainingHelper(inputs = target_data, sequence_length= length)
train_decoder = tf.contrib.seq2seq.BasicDecoder(stack_lstm,train_help,c)
train_output, _ = tf.contrib.seq2seq.dynamic_decode(train_decoder, maximum_iterations=length)
# predict_decoder
with tf.variable_scope('decode', reuse=True):
# 将每次输出的logits中最大值的下标所对应的embedding向量作为下次输入
predict_help = tf.contrib.seq2seq.GreedyEmbeddingHelper(decoder_embedding_table, start_token, end_token)
predict_decoder = tf.contrib.seq2seq.BasicDecoder(stack_lstm, predict_help, c)
predict_output, _ =tf.contrib.seq2seq.dynamic_decode(predict_decoder, maximum_iterations=length)
return train_output, predict_output
|