预训练
所谓预训练,就是使用他人已经训练好的网络,在此基础上进行部分网络层的训练
在使用神经网络处理问题时,我们通常有两种处理方法:
- 自己搭建网络并训练,这会耗费我们许多的时间及精力,最后可能还得不到较好的结果
- 使用他人已经训练好的、结果优秀的网络,但我们很可能找不到和我们目的完全一致的网络
在这种情况下,我们可以选择退一步,寻找与我们目的相似的网络模型,比如我们需要处理场景分辨的问题,那么我们就可以去寻找在分类问题上表现优秀的网络,保持其大部分网络参数不变,简单的对一些网络层,比如最后的全连接分类网络,进行修改训练,从而简单快速地获得我们需要的网络
VGG16
VGG16是在ILSVRC 2014中取得第二名卷积神经网络,其结构简单粗暴,通过逐渐增加网络深度来提高网络性能,不过结果却十分有效。很多模型的预训练方法就是使用的VGG16,所以有必要掌握其构造
VGG16提出于Paper《Very Deep Convolutional Networks for Large-Scale Image Recognition》
其结构如下图D列,而E列则是VGG19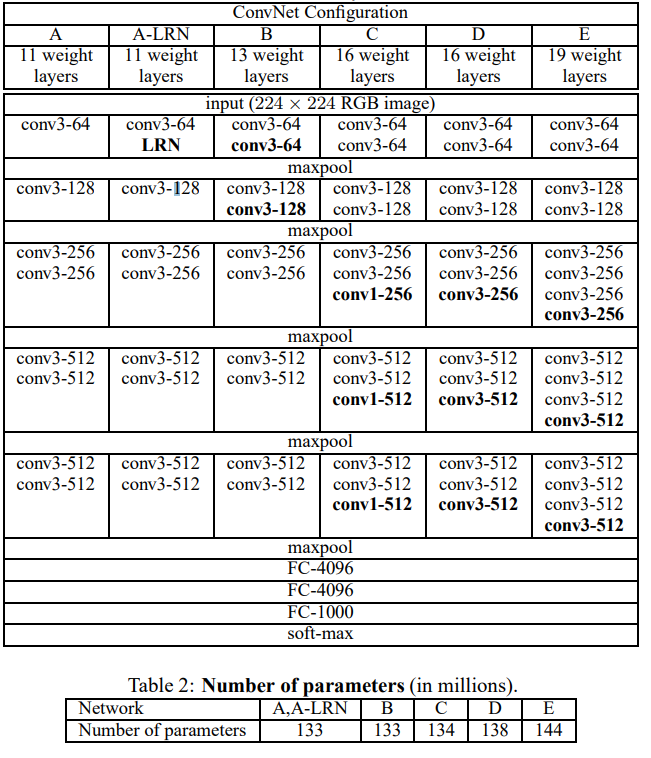
分析
- convX-Y: 卷积层,卷积核大小为X,卷积核个数为Y,步长为1,padding为same
- maxpool: 池化层,区域大小为2,步长为2,padding为same
- FC-X: 全连接层,输出单元个数为X
各层均使用relu激活
从这可以看出VGG16的参数空间很大,自己训练一个VGG16通常要花费十分大的时间,好在有公开的VGG16预训练模型供我们使用
例子
第一部分
$224 \times 224 \times 3$ -> $112\times 112 \times 64$
- 卷积层,卷积核大小为$3\times 3$,数量为64,步长为1,padding为same
- relu激活
- 卷积层,卷积核大小为$3\times 3$,数量为64,步长为1,padding为same
- relu激活
- maxpool,区域大小为$2\times2$,步长为2,padding为same
第二部分
$112\times 112 \times 64$ -> $56\times 56 \times 128$ - 卷积层,卷积核大小为$3\times 3$,数量为128,步长为1,padding为same
- relu激活
- 卷积层,卷积核大小为$3\times 3$,数量为128,步长为1,padding为same
- relu激活
- maxpool,区域大小为$2\times2$,步长为2,padding为same
Tensorflow实现
1 | def VGG16(): |