Attention
所谓Attention,就是注意力,我们知道人在做事时注意力分布是不均匀的,无论是看图像、还是翻译单词,都是有着重点,这也就是Attention机制提出的根本
此机制于《Neural Machine Translation by Jointly Learning to Align and Translate》中提出
<img src=”img/图片名.jpg>
回顾
在介绍此模型前,先回顾一下Seq2Seq的基础模型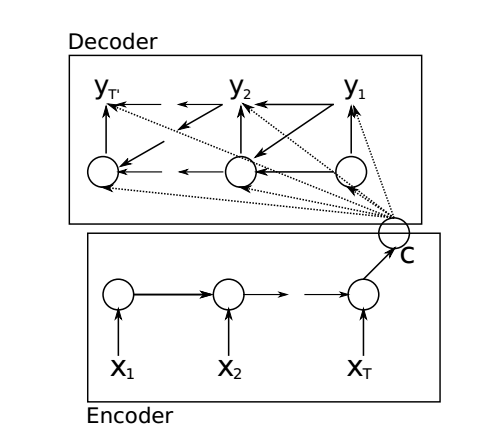
- Encoder端中
我们计算了一些东西 - Decoder端
我们对所有的输出简单的让$c = q(h_0,h_1,…,h_T) = h_T$得到了我们需要的语义向量C
我们想到按这样的结构
- $h_i$和下文无关,不太合理
- $c$是一个固定向量,失去了我们想要的注意力,可能过于简单
事实证明在解决了以上两点问题后Seq2Seq模型的性能有了很大的提升
正题
Encoder
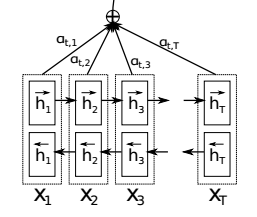
我们先将目光集中在Encoder处,与BasicSeq2Seq对比主要变化有两个
- 在新模型中,采用了BiRNN(双向RNN)代替BasicRnn进行处理
- 我们会利用到每一个生成的$h_i$
Decoder
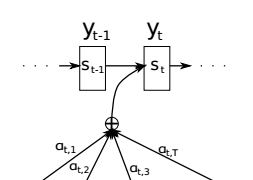
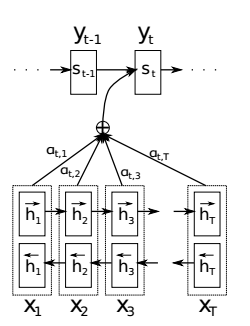
- 在产生$y_i$时我们将$c$用对应的$c_i$替换,并修改了$c$的产生方式,即修改了$q$函数
通过这种方法使得每一个$yi$所对应的语义向量$c_i$都不相同,原序列中的某一部分对$y_i$的影响越大,那么$y_i$会越关注它,即对应的$\alpha{i,j}$越大
而为了保证$\sum \alpha=1$,我们设初始权重为$e{i,j}$,初始权重的加和不为一,但满足$Y_i$越受$X_j$影响,$e{i,j}$越大
这就达到了将权重归一化的目的
那么如何求得$e_{i,j}$呢?
我们再建立一个浅层网络,使得
这里$s_{i-1}$是Decoder端的隐状态,$h_j$是Encoder端的隐状态
我们把这个网络接入主网络中,那么在梯度下降的时候就会同时对其进行更新
仅供参考的Tensorflow实现
惊了,越写越感觉自己的理解出了问题,先查查资料
只是实现的简化版,实际使用中还需要进行一些处理
大概是这样吧。1
2
3
4
5
6
7
8
9def Encoder_Attention(embed_input, rnn_size):
f_cell = tf.nn.rnn_cell.LSTMCell(rnn_size)
b_cell = tf.nn.rnn_cell.LSTMCell(rnn_size)
(f_output,b_output),(f_state,b_state) = tf.nn.bidirectional_dynamic_rnn(cell_fw= f_cell,
cell_bw=b_cell,
inputs=embed_input)
encoder_outputs = tf.concat((f_output,b_output),2)
return encoder_outputs
1 | def Decoder_Attention(embed_target, encoder_outputs,rnn_size, length,batch_size,decoder_embedding_table, start_token, end_token): |