ShowAndTell
该模型的作用就是看图说话,其背后的原理和Seq2Seq一致,只要弄懂了BasicSeq2Seq与Seq2Seq的Attention变体,ShowAndTell就很好理解了
Show and tell
从序列到序列至图像到序列的开创性文章
Show and Tell: A Neural Image Caption Generator
其内容很容易概括
将BasicSeq2Seq的Encoder端换成VGG16
通过CNN压缩语义向量,随后传入与BasicSeq2Seq相同的Decoder
Show, attend and tell
由文章Show, Attend and Tell: Neural Image Caption Generation with Visual Attention提出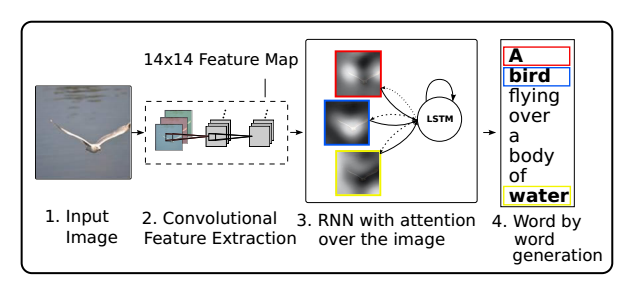
在Show and tell的基础上加入了attention机制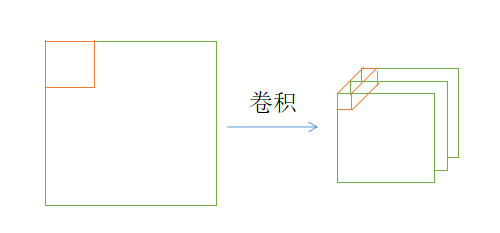
我们知道,原图中的某块区域在卷积后,直观上会变得”窄长”,于是我们就把卷积后的每一条向量看成是对原图片的某块区域的特征提取
在去除VGG16中的全连接层后,我们把图片送入网络,就得到了卷积后的图片,即是Encoder端需要的$h_t$