pix2pixHD
pix2pixHD论文(arxiv)
整理一下对pix2pixHD的理解,不保证完全准确。
总览
pix2pixHD是一种用来生成超高分辨率图像的网络,对比pix2pix的主要改变如下
- 网络结构
- 输入图像
- loss设计
这些设计使得pix2pixHD能够得到更好的结果,且对同一个输入可以得到不同的输出,改善了pix2pix一对一映射的缺点。总体来说,模型有着比较好的解释性。
网络结构
“网络结构”部分为instance map -> generator -> discriminator,这部分也是pix2pix论文中主要讨论的问题。
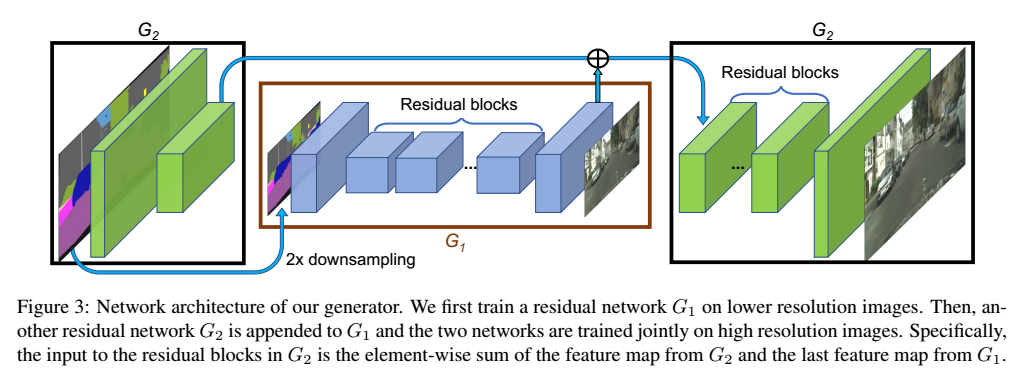
pix2pixHD将generator拆分成G1(全局生成网络)、G2(局部提升网络)。
- G1先对instance map进行2x downsampling,再将下采样后的结果进行处理。卷积 -> 残差 -> 反卷积;得到的反卷积结果直接与G2的卷积结果进行相加
- G2直接对instance map进行卷积,之后与G1输入的结果相加,再送入ResNet,对反卷积后的结果进行一次卷积得到generated
- 对于更高分辨率的图片生成,可以继续嵌套网络
论文里总共设计了三个discriminator分别对不同尺寸(2x、4x downsampling)下原始图片和生成图片进行判别,所有的discriminator网络结构相同(指卷积核大小及维度变化)
输入图像
论文认为semantic label map没有对相同类别物体的不同对象进行区分,而将instance-level semantic label map输入网络在实现上不太实际,文章认为instance-level semantic label map提供的最大信息在于不同对象间的边界信息,于是将通过instance-level semantic label map计算出boundary map与semantic label map进行concate作为网络输入
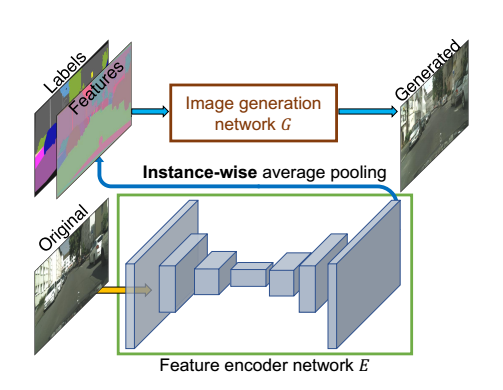
除此外还添加了一个embedding网络生成一个features与上述两图一起concate作为输入,通过这种方式能对生成图片的风格、纹理等进行控制
loss设计
feature matching loss在通常loss的基础上,加入了判别器卷积过程中合成图片与目标图片的高维特征差(L2),可参考PatchGAN
可能会用到的其他知识
- CNN/VGG
- GAN
- CGAN
- PatchGAN
- ResNet
- U-Net(maybe)